


کاربرد تکنیکهای پردازش زبان طبیعی در پردازش متن
کاربرد تکنیکهای پردازش زبان طبیعی در پردازش متن (بخش ششم)
مشاهده ی تمام آموزش های NLP
یکی از حوزههایی که در سالهای اخیر توجه پژوهشگران زیادی را به خود جلب کرده است غلطیابی و نرمالسازی متن است. نرمالسازی به معنای تبدیل متن به شکل استاندار و نوشتاری زبان موردنظر است (jurafsky and martin, 2009). در این بخش در ابتدا به تعریف مبانی نظری موضوع موردنظر پرداخته خواهد شد. سپس در بخشهای بعدی نمونهای از کدهای غلطیابی و نرمالسازی متن فارسی نیز اضافه میگردد.
کاربرد تکنیکهای پردازش زبان طبیعی در پردازش متن (بخش ششم)
مشاهده ی تمام آموزش های NLP
یکی از حوزههایی که در سالهای اخیر توجه پژوهشگران زیادی را به خود جلب کرده است غلطیابی و نرمالسازی متن است. نرمالسازی به معنای تبدیل متن به شکل استاندار و نوشتاری زبان موردنظر است (jurafsky and martin, 2009). در این بخش در ابتدا به تعریف مبانی نظری موضوع موردنظر پرداخته خواهد شد. سپس در بخشهای بعدی نمونهای از کدهای غلطیابی و نرمالسازی متن فارسی نیز اضافه میگردد.
مقدمه
با گسترش فضای اینترنتی و تولید محتوا، خصوصاً محتوای متنی، لزوم صحیح بودن متون تولیدشده از اهمیت ویژهای برخوردار است. خبر، بهعنوان یکی از مهمترین تولیدات در فضای مجازی بیشترین سهم از حجم محتویات تولیدشده را به خود اختصاص داده است، لذا ویرایش این متون الکترونیکی تولیدشده به روش انسانی بسیار وقتگیر خواهد بود. ابزارهای هوشمندی مثل غلطیابها میتواند به ویراستاران در این زمینه کمک شایان بنماید[1].
الف: تاریخچه
اولین غلطیاب هوشمند برای زبان انگلیسی در سال 1980 تولید شد[2]. سپس پلک و زامورا [3] با استفاده از یک واژهنامه غلطیاب جدیدی را طراحی نمودند. اتول و الیوت [4] با استفاده از روش ان-گرم غلطیابی را جهت تشخیص اشتباهات موجود در متن طراحی کردند. مانگو و بریل [5] روش جدیدی را جهت پیشنهاد کلمه صحیح ارائه کردند. این روش بر اساس تغییر جایگاه نویسههای کلمه طراحی گردید.
Regular Expressions در NLP (بخش پنجم)
ب : روشهای تشخیص و تصحیح غلطهای املایی
در ادامه این بخش به بررسی روشهای غلطیابی و تصحیح این غلطها پرداخته خواهد شد. ابتدا انواع غلطهای املایی در متون بررسی میشود. جدول نمونهای از غلطهای املایی را نشان میدهد:
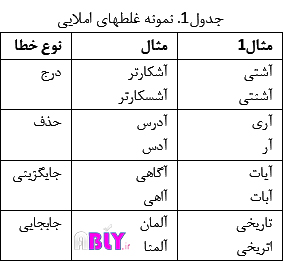
در جدول 1 نمونه غلطهای معمول املایی قابل مشاهده است. در این نوع غلطها چهار حالت عمده درج نویسه در کلمه، حذف نویسه از کلمه، جایگزینی نویسه به جای نویسه دیگر و در نهایت جابجایی نویسههای همجوار اتفاق میافتد. در ادامه روشهای غلطیابی و تصحیح این نوع غلطها مورد بررسی قرار میگیرد.
از مهمترین روشهای تشخیص خطاهای املایی میتوان به روش اِن-گرم و روش مبتنیبر واژهنامه اشاره کرد[6]. در روش اِن-گرم مجموعهای از حروف متوالی یک رشته به طول n درنظر گرفته میشود. اِن-گرمهای یکحرفی را یونی-گرم، دو حرفی را بای-گرم و سهحرفی را ترای-گرم مینامند. هر اِن-گرم یک رشتهی ورودی میباشد که با جدولی از اِن-گرمهای صحیح که از قبل آماده شده مقایسه میشود. در صورت عدم وجود یا رخداد پایین رشتهی ورودی سیستم آن را خطا تشخیص میدهد. روش مبتنیبر واژهنامه، هر واژهی ورودی را در واژهنامه جستوجو میکند. اگر واژه در واژهنامه موجود باشد آن را صحیح تشخیص میدهد در غیر اینصورت آن را در فهرست واژههای نادرست ذخیره میکند[8][7]. در ادامه روشهای تصحیح خطاهای املایی مورد بررسی میشود.
1 . روش حداقل فاصله ویرایشی: حداقل فاصله ویرایشی یکی از سادهترین روشهای غلطیابی محسوب میشود که غلطیابی را بر مبنای کمترین خطای کاربر انجام میدهد[9]. بنابراین برای هر واژه ابتدایی ترین عملیات ویرایشی (درج، حذف، جایگزینی) را که منجر به تبدیل واژهها به ناواژهها میشود را در نظر میگیرد
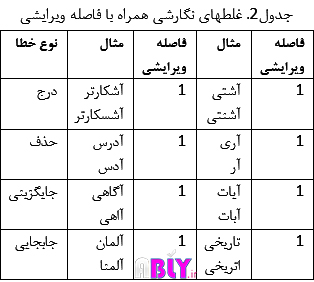
در جدول 2 فاصله ویرایشی مربوط به هر چهار نوع رایج غلطهای املایی نیز آورده شده است. برای مثال در عملیات درج، میان کلمات آشکارتر و آشسکارتر یک نویسه اضافی وارد شده است که فاصله ویرایشی بین این دو کلمه برابر با یک میباشد . لونشتاین نیز در از روشی مشابه همین روش استفاده کرد با این تفاوت که او عملیات ویرایشی درج و حذف و جابجایی را در مدل خود به کار برد[10].
منابع:
[1] Leacock, C., Chodorow, M. & Gamon, M. (2010). Automated grammatical error detection for language learners. Synthesis Lectures on Human Language Technologies, 3(1), 1-134.
[2] Peterson, J. L. (1980). Computer programs for detecting and correcting spelling errors. Communications of the ACM, 23, 676-687.
[3] Pollock, J. J. & Zamora, A. (1984). Automatic spelling correction in scientific and scholarly text. Communications of the ACM, 27, 358-368.
[4] Atwell, E. & Elliott, S. (Eds.). (1987). Proceedings from The Computational Analysis of English. London: England.
[5] Mangu, L. & Brill, E. (Eds.). (1997). Proceedings from Proceeding of the 14thInternational Conference on Machine Learning. San Francisco: USA.
[6] [6] (Kukich 1992) Kukich, K. Techniques for automatically correcting words in text, ACM Computing Surveys. Vol.24, No. 4 (Dec. 1992), pp. 377-439, 1992.
[7] Ahmed, F., Luca, W. & Nürnberger, A. (Eds.). (2007). Proceedings from 8th International Conference on Intelligent Text Processing and Computational Linguistics. Mexico City: Mexico.
[8] Wasala, A., Weerasinghe, R. & Gamage, K. (Eds.). (2006). Proceedings from the COLING/ACL Main Conference Poster Sessions. Sydney: Australia.
[9] Damerau, F. (1964). A technique for computer detection and correction of spelling errors. Comm. ACM, 7(3), 171-176.
[10] Wasala, A., Weerasinghe, R., Pushpananda, R., Liyanage, C. & Jayalatharachchi, E. (2010). A Data-Driven Approach to Checking and Correcting Spelling Errors in Sinhala. The International Journal on Advances in ICT for Emerging Regions, 3, 11-24.
[11] Bhirud, N. S., Bhavsar, R. & Pawar, B. (2017). Grammar chekcers for natural languages: A review. International Journal on Natural Language Computing (IJNLC), 6(4), 1-13.
[12] Zhao, H., Cai, D., Xin, Y., Wang, Y. & Jia, Z. (2017). A hybrid model for chinese spelling check. ACM Transactions on Asian and Low-Resource Language Information Processing (TALLIP), 16(3), 34-56.
[13] Arif Billah Al-Mahmud Abdullah, Ashfaq Rahman, “A Generic Spell Checker Engine for South Asian Languages” , IASTED 2003, November 3-5 2003
[14] K. Shaalan, A. Allam, A. Gomah. Towards Automatic Spell Checking for Arabic, In Proceedings of the 4th Conference on Language Engineering, Egyptian Society of Language Engineering (ELSE), PP. 240-247, Egypt, Oct. 21-22, 2003.
[15] Bick, Eckhard. 2006. «A Constraint Grammar Based Spellchecker for Danish with a Special Focus on Dyslexics». In: Suominen, Mickael et al. (ed.) A Man of Measure: Festschrift in Honour of Fred Karlsson on his 60th Birthday. Special Supplement to SKY Jounal of Linguistics, Vol. 19 (ISSN 1796-279X), pp. 387-396. Turku: The Linguistic Association of Finland
[16] Brill, E. and R. Moore. 2000. An improved error model for noisy channel spelling correction. In Proceedings of the ACL 2000, pages 286-293.
[17] Ayegba, S. F., Ugbedeojo, M., Jessica Chinezie, B. & Abu, O. (2017). Igala language spell checker. Current Journal of Applied Science and Technology, 23(2), 1-9.
[18] Mandal, P. & Hossain, M. M. (Eds.). (2017). Proceedings from 2017 IEEE International Conference on Imaging, Vision & Pattern Recognition (icIVPR). Dhaka: Bangladesh.
[19] Alva, C. & Marcos, A. (Eds.). (2017). Proceedings from the First Workshop on Subword and Character Level Models in NLP. Copenhagen: Denmark.
[20] Sorokin, A. (Eds.). (2017). Proceedings from the 6th Workshop on Balto-Slavic Natural Language Processing. Valencia: Spain.
[21]Sarma, B., Goswami, D. & Goswami, G. (2017). Assamese spell checker design and implementation. International Journal of Modern Trends in Engineering and Research, 3(2), 44-47
در بخش بعدی الگوریتمهای تشخیص و تصحیح بیشتری به همراه پژوهشهای انجامشده در حوزه غلطیابی و نرمالسازی متن فارسی معرفی خواهد شد.
"تهیه شده در سایت ABLY"
لیلا میری
مطلب مفیدی بود ممنون