


آموزش NLP - پردازش زبان طبیعی
آموزش فارسی NLP (بخش دوم)
ان ال پی چیست - بخش اول
-
عبارات منظم در پردازش زبان طبیعی
-
نظریه زبانها و ماشینها در پردازش زبان طبیعی
عبارات منظم، نظریه زبانها و ماشینها و پردازش زبان طبیعی
در این بخش از آموزش NLP به زبان فارسی درمورد کاربرد عبارات منظم در پردازش زبان طبیعی فارسی بحث خواهد شد. سپس بهصورت اجمالی اطلاعاتی درمورد نظریه زبانها و ماشینها ارائه میگردد. درنهایت با استفاده از زبان برنامهنویسی پایتون چندین مثال عملی و کاربردی ارائه خواهد شد.

آموزش natural language processing به زبان فارسی (بخش دوم)
-
عبارات منظم در NLP
-
نظریه زبانهاو ماشینها در NLP
آموزش فارسی NLP (بخش اول)
عبارات منظم، نظریه زبانها و ماشینها و پردازش زبان طبیعی
در این بخش از آموزش NLP به زبان فارسی درمورد کاربرد عبارات منظم در پردازش زبان طبیعی فارسی بحث خواهد شد. سپس بهصورت اجمالی اطلاعاتی درمورد نظریه زبانها و ماشینها ارائه میگردد. درنهایت با استفاده از زبان برنامهنویسی پایتون چندین مثال عملی و کاربردی ارائه خواهد شد.
1. عبارات منظم (Regular Expressions)
در دنیای کنونی و با گسترش روزافزون محتوا در فضای مجازی و حقیقی بدون شک استخراج داده از این محتوای بدون ساختار کار مشکلی خواهد بود. قطعاً عامل انسانی به دلیل خستگی مفرط و عدم دقت کافی، باید از کامپیوترها در جهت استخراج داده از فضای مجازی استفاده نماید؛ اما این سؤال مطرح میشود که چگونه باید از کامپیوترها در جهت حل این مسئله مهم استفاده نمود.
در سالهای اخیر به دلیل گستردگی وب تلاشهای بسیاری در جهت استخراج داده از این فضای بزرگ انجام شده است که باعث به وجود آمدن الگوریتمهای بسیار کاربردی نیز شده است. قبل از هر چیز باید بتوانیم زبان انسان را برای کامپیوتر مدل کنیم. مدل کردن یعنی الگوهایی از زبان استخراج کنیم که بتوانیم این الگوها را در جایی ذخیره کرده و از این الگوها استفاده نماییم. یکی از راههای مؤثر برای مدل کردن زبان انسان استفاده از ماشینهای متناهی (Finite state automata) میباشد. با استفاده از FSA بهراحتی میتوان بخش اعظمی از زبان انسان را برای کامپیوتر مدل کرد و الگوهای زبان انسان را استخراج نمود.
FSA چیست؟ | FSA در پردازش زبان طبیعی
FSA تنها یک مدل ریاضی نیست بلکه یکی از ابزارهای مهم در پردازش زبان طبیعی به شمار میرود که بهوسیله آن میتوان عبارات منظم (regular expression) را در کامپیوتر شبیهسازی نمود. FSA، مدل مخفی مارکو، مدل N-gram را میتوان از انواع مدلهای زبانی در نظر گرفت که نقش بسزایی در پردازش زبان طبیعی ایفا میکنند.
یکی از الگوریتمهای موفقی که در علوم کامپیوتر به وجود آمد عبارات منظم یا RE میباشد (Jurafsky and martin, 2009). از این ابزار بیشتر برای جستجو در متون بزرگ استفاده میگردد. مثلاً در نظر بگیرید که اگر بخواهیم از یک متن بسیار بزرگ و طولانی و بدون ساختار، همه ایمیلها یا همه شماره تلفنها را استخراج کنیم با چه مشکلی روبهرو خواهیم بود. از این ابزار برای جستجو در سیستمعامل UNIX و همچنین در برنامه محبوب Microsoft word نیز استفاده شده است. RE در ابتدا توسط (Kleene, 1996) معرفی گردید که برای جستجوهای ساده استفاده میشد.
RE در پردازش زبان طبیعی
تعریف رسمی RE بهصورت زیر میباشد:
یک نمادسازی جبری برای مشخص کردن یک رشته (jurafsky and martin, 2009). RE الگویی خاص را در متن جستجو مینماید و اگر الگوی موردنظر در متن پیدا شد، متن یافتشده برگردانده میشود. اگر بخواهیم RE را تشبیه کنیم، RE شبیه یک ماشین است که ورودی آن متن است و خروجی آن نیز متنها و الگوهای یافتشده میباشد. موتور این ماشین همان الگوهایی است که قصد داریم در متن پیدا شود.
- شماره تلفن
- ایمیل
- آدرس وبسایت
- تمامی کلماتی که با حروف خاص (مثلاً با حرف "ب") شروع میشوند
- اسامی خاص
- و ...
الگوهایی هستند که میتوان توسط RE از متون مختلف و بدون ساختار استخراج نمود.
1.1 الگوهای ساده در RE
سادهترین نوع الگو در RE یک رشته محسوب میشود. در تصویر 1 نمونهای از کد زبان برنامهنویسی پایتون را مشاهده میکنید که از RE جهت پیدا کردن یک رشته استفاده شده است:
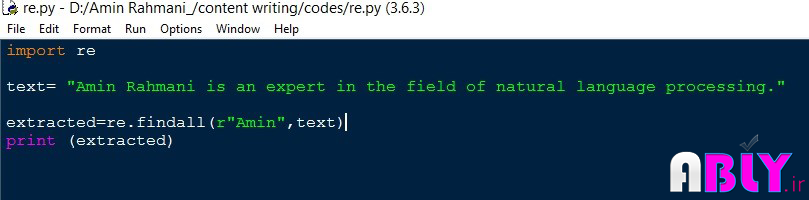
تصویر 1. استفاده از RE برای جستجوی یک رشته ساده
با استفاده از دستور import re کتابخانه مربوط به عبارات منظم فراخوانده میشود. سپس با استفاده از تابع findall تمامی الگوهایی که در تابع بهعنوان آرگومان اول وارد شده است جستجو میشود. تابع findall دو آرگومان را دریافت میکند:
Findall (pattern, text)
Pattern که همان الگو است که حتماً باید بهصورت رشته وارد گردد و قبل از الگو نیز باید حرف r قرار بگیرد و text متن موردنظری است که جستجو در آن انجام میپذیرد.
در تصویر 2 نتیجه جستجو نمایش داده شده است:
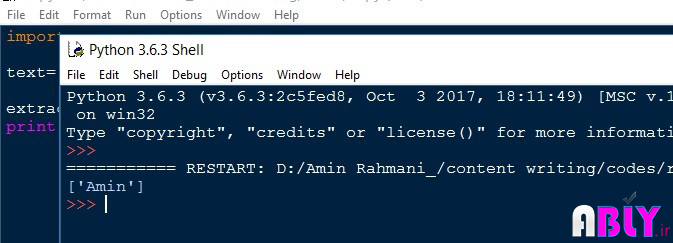
تصویر 2. نتیجه جستجو بهوسیله RE
تابع دیگری که در کتابخانه RE توسط برنامه نویسان بسیار استفاده میگردد تابع Match میباشد. خروجی این تابع یک مقدار Boolean است. در تصویر 3 نمونهای از کد تابع match و نتیجه آن نشان داده شده است:
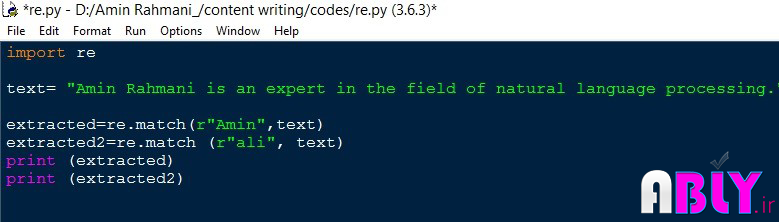
تصویر 1-13. نمونه کد تابع match در RE
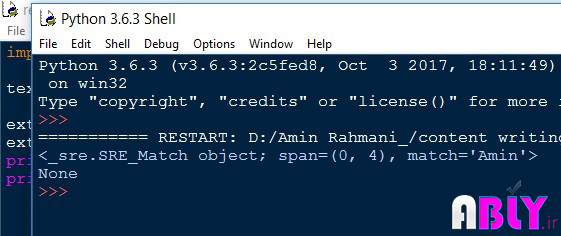
تصویر 2-3 نتیجه کد تابع match
اگر الگوی موردنظر توسط تابع match پیدا شود، خروجی تابع یک است در غیر این صورت خروجی تابع None میباشد. در تصویر 4 مثالهای بیشتری نمایش داده شده است:

در بخش های بعدی آموزش natural language processing ما بیشتر راجع به عبارات منظم در nlp صحبت خواهیم کرد.
"با تشکر از توجه شما دوستان عزیز"
"تهیه شده در مجموعه ABLY"
ع
بسیار عالی بی صبرانه منتظر بخش های بعدی هستیم
مدیروب سایت
حتما دوست عزیز